Nieman Foundation at Harvard

Say you’re reading a long story — one that picks up on a lot of other fast-moving threads in the news, some of which you haven’t been following. It makes repeated mention of people whose significance you’ve forgotten. You could open up another tab, throw their names into Google, and scan through the results. But who wants to find other articles just to help you understand the one you’re already reading?
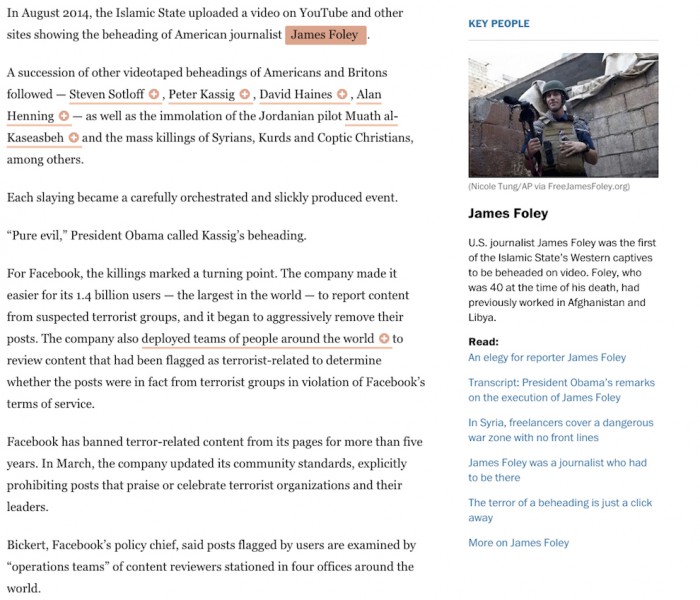
Solving the problem of context — the fact that different readers bring different amount of knowledge to a story — has been one of the primary quests of the past half decade. Vox’s Card Stacks, Circa’s atomized stories, “9 questions about Syria you were too embarrassed to ask” — all are attempts to build background knowledge into daily news production. And in-story footnotes are hardly new; those with slightly longer memories may recall Apture, which aimed to automate a similar result.
What makes the Post’s Knowledge Map more interesting than some other efforts its aim to use to create a single underlying knowledge base for Post stories — one that can be automatically responsive to stories at the word level. And it might have revenue potential.
Knowledge Map debuted on a story from the Post’s “Confronting the Caliphate” series. In its announcement, the Post had hinted that down the line, it could automatically mine “big data” to “surface highly personalized and contextual data for both journalistic and native content.”
What does highly personalized content look like for readers? And what does the potential automation mean for reporters trying to strike a balance between overstuffing a story with context and keeping it so lean readers are lost?
“You go on vacation and then all this stuff happened — how can we help pick up the pieces for these readers?” said Sarah Sampsel, the Post’s director of digital strategy and design, of the thinking behind the feature.
Knowledge Map sprouted a few months ago out of a design sprint (based on a five-day brainstorming method outlined by Google Ventures) that included the Post’s New York-based design and development team WPNYC and members of the data science team in the D.C. office, as well as engineers, designers, and other product people. After narrowing down a list of other promising projects, the team presented to the Post newsroom and to its engineering team an idea for providing readers with better summaries and context for the most complicated, long-evolving stories.
That idea of having context built into a story “really resonated” with colleagues, Sampsel said, so her team quickly created a proof-of-concept using an existing Post story, recruiting their first round of testers for the prototype via Craigslist. Because they had no prior data on what sort of key phrases or figures readers might want explained for any given story, the team relied on trial and error to settle on the right level of detail.
 “We just tried to use common sense to figure out where people might have a question about something in particular but the reporters just didn’t have the space to dive into,” said WPNYC user experience designer Blake Hunsicker, who along with the Post’s digital foreign editor Swati Sharma picked out the phrases to illuminate. (Hunsicker helped write the supplemental information for the Islamic State story in which Knowledge Map debuted.) “As a rule, we just tried to use more conversational writing, reworked some of the supplements over several times, and tried again and again and again.”
“We just tried to use common sense to figure out where people might have a question about something in particular but the reporters just didn’t have the space to dive into,” said WPNYC user experience designer Blake Hunsicker, who along with the Post’s digital foreign editor Swati Sharma picked out the phrases to illuminate. (Hunsicker helped write the supplemental information for the Islamic State story in which Knowledge Map debuted.) “As a rule, we just tried to use more conversational writing, reworked some of the supplements over several times, and tried again and again and again.”
Recruited users who gave feedback on the earliest version seemed to prefer “shorter and straight-to-the-point supplements that also stressed a few important things, rather a definition about a place or person,” Hunsicker said — so he opts for bullet points whenever possible when writing.
The Post team is still analyzing data from the public rollout of Knowledge Map a few weeks ago to figure out how users’ engagement with a Knowledge Map story is different from that with a story in a traditional layout. They’re also studying which supplements attract more readers or lead to more clicks on other supplements, according to Sampsel and Sam Han, the Post’s engineering director for data science. They’re examining whether the position of a link in a sentence or the frame on a button might be inviting more clicks; they say it’s still too early to draw any conclusions.
 “We saw much better engagement on the story with the Knowledge Map initially,” Sampsel said. “But that was publicized, and includes that big push and everything, so we are taking a longer time to see how the engagement data unfolds.” But, at least anecdotally, reactions to the added context have been “overwhelmingly positive,” she said.
“We saw much better engagement on the story with the Knowledge Map initially,” Sampsel said. “But that was publicized, and includes that big push and everything, so we are taking a longer time to see how the engagement data unfolds.” But, at least anecdotally, reactions to the added context have been “overwhelmingly positive,” she said.
The key part of this sort of added context is that it’s reusable; Vox doesn’t have to rebuild its fracking card stack from scratch for every fracking story. When more and more stories in the future get the Knowledge Map treatment, Han says, “we’ll have a database of all these supplements, who has clicked on them, and how many times. So when a reporter has written the story, an engine will analyze the sentence and make a recommendation to say, ‘these are the supplements available,’ and let the reporter and editor decide whether or not to use them.”

The potential specificity of these supplements also opens up new avenues for attracting advertisers, Han said. Every supplement will be tagged with categories such as “technology,” “national security,” or “business.” So when readers click on a keyword in a story and switch their focus from reading the main article to reading the supplement, they might see a topical advertisement attached to that particular supplement. (Currently on most Post stories, ads appear in the main body of a story as the reader scrolls down, every few paragraphs.)
Full-blown implementation of this sort is still a ways off, Han and Sampsel said, and the team is still working through how automation will impact editorial workflow. “We’ll want to run additional tests, potentially with the same topic, but we’re also looking into other topics that might interest people,” Sampsel said. “Ideally we want to run something like this across more stories, so a reader could link together common themes between them.”




